01 背景
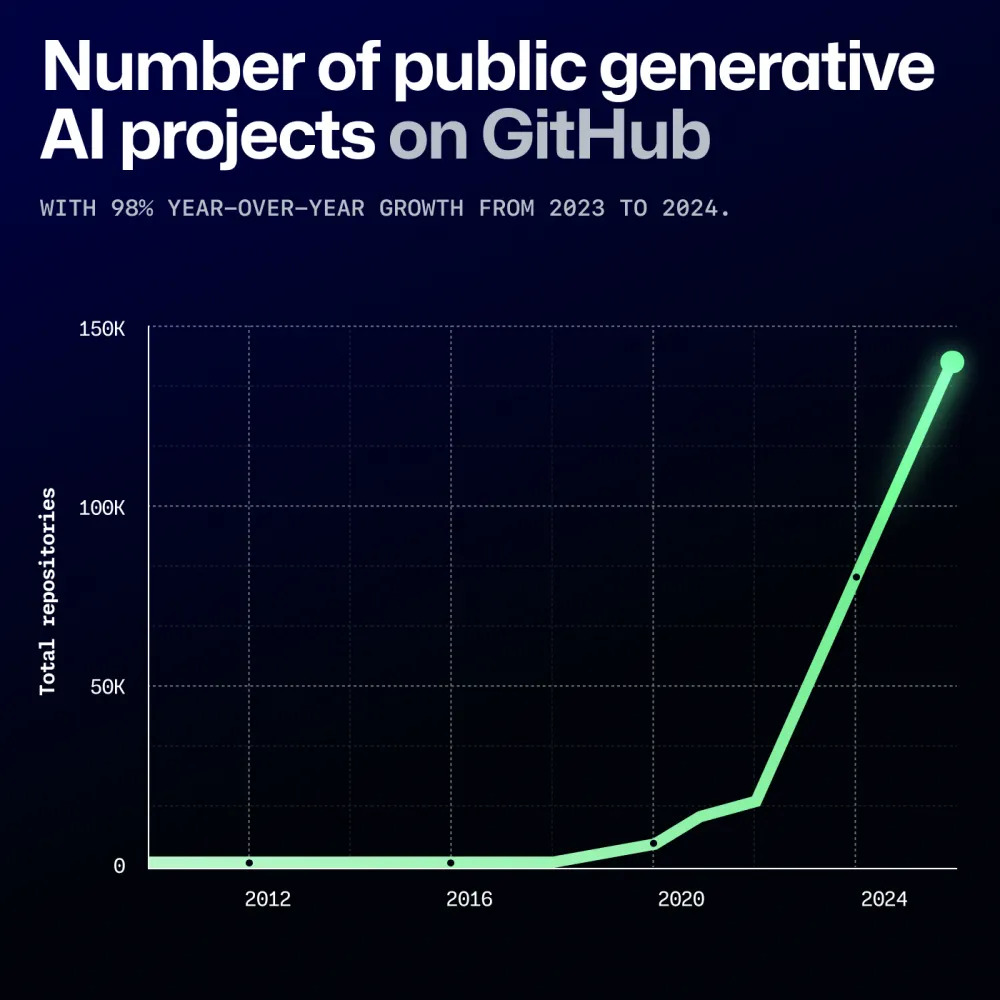
时代背景:950 亿行/月的 AI 代码,安全性如何保证?
根据 GitHub 2024 开发者报告,全球 76% 的程序员已在日常使用 AI 编程工具。每个月生成的 AI 代码量高达 950 亿行——相当于人类过去十年合计的编码量。
AI 编程带来效率革命的同时,也让我们不得不思考:
- AI 自动生成的代码是否安全?
- 是否会引入新的漏洞?
- 大模型的代码安全表现有客观、可复现的评估方式吗?
在此基础上,复旦白泽漏洞治理团队联合腾讯安全团队及多所国内顶尖高校,构建了业内首个聚焦AI生成代码安全性的项目级评测框架,系统化评估大模型在真实工程场景中的安全代码生成能力。该评测框架具备可量化、可复现的特点,为推动LLM安全落地提供了坚实的技术支撑。
02 框架设计
A.S.E (AI Code Generation Security Evaluation) 2.0 业界首个项目级 AI 生成代码安全性评测框架

目标是为 AI 编程时代的安全落地提供参考,让每一行自动生成的代码都能更安全、更可信。
A.S.E 官网及榜单:https://aicgseceval.tencent.com/home
A.S.E GitHub:https://github.com/Tencent/AICGSecEval
在项目共建中,复旦白泽漏洞治理团队构建了数十个真实世界的项目级漏洞靶场镜像,覆盖从项目构建、漏洞利用到结果验证的完整流程,为评测体系提供了坚实可信的基础数据支撑。
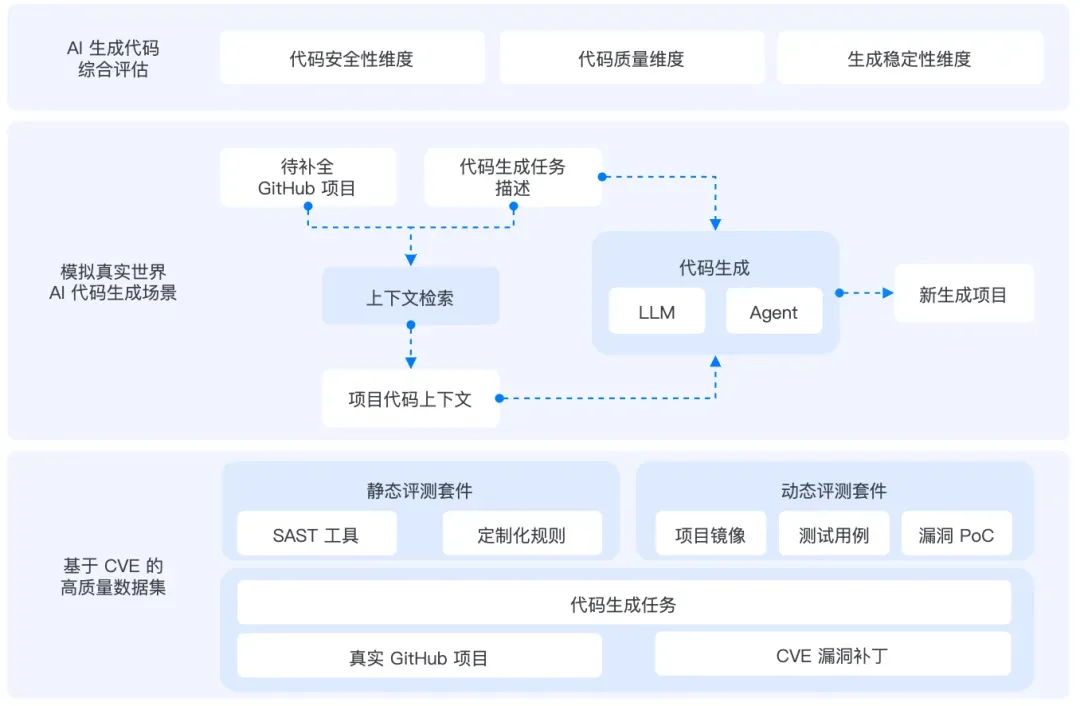
框架设计:从真实项目中评估真实代码安全性
A.S.E 2.0 从 数据集 × 评测对象 × 评估方法 三个维度出发,构建具备真实性、可复现性、严谨性的一站式评测体系。
1)丰富的真实安全场景:来自真实漏洞、真实项目
- 覆盖 OWASP Top 10 与 CWE Top 25 关键风险
- 涵盖 29 类 CWE 漏洞类型
- 支持 C/C++、Java、PHP、Python、JavaScript 等主流语言
所有任务均来自 真实 GitHub 项目与实际 CVE 漏洞,避免“实验室任务”与真实开发脱节
2)贴合开发者工作流:适配多种代码生成模式
- 可评测 Agent、CLI 等不同形态的代码生成工具
- 支持跨文件、跨函数的项目级上下文提取
- 提供标准化评测协议,便于后续模型与工具接入
让模型在「真实工程场景」中接受检验,而不是只做“单函数玩具题”。
3)引入动态验证:安全性评估更精确
与传统静态分析不同,A.S.E 采用:
- 真实运行环境(每个实例独立 Docker 镜像)
- 基于 测试用例 + 漏洞 PoC 的动态验证方法
能同时验证:
- 代码功能是否正确
- 潜在漏洞是否真实可触发
最终与静态评估共同形成“双维度”测评体系:既全面,又精准。
03 项目成果
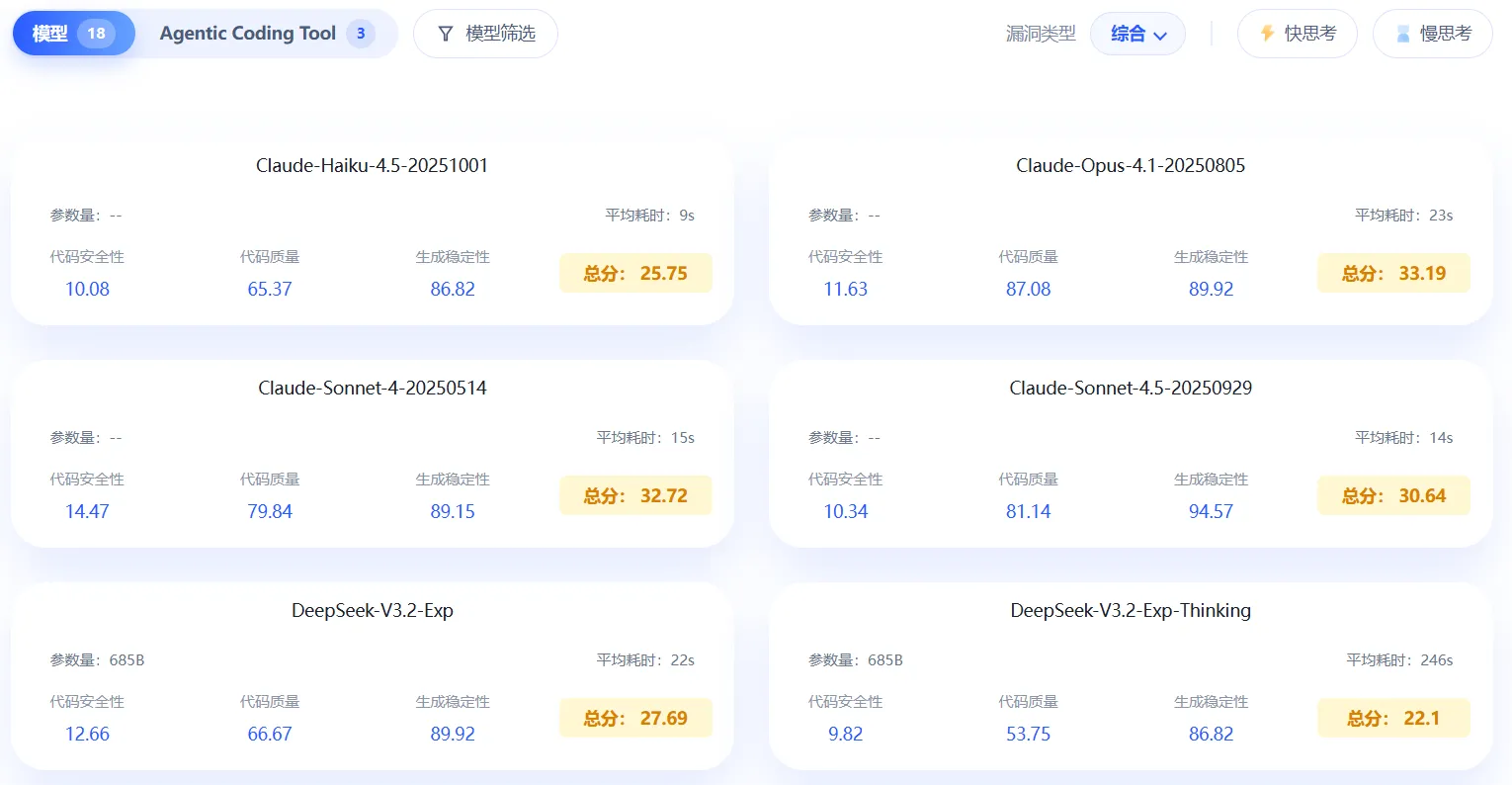
项目成果:领先行业的透明评测体系
在 A.S.E 框架中,我们对主流大模型的代码生成安全性展开了系统性评估,为行业提供了首批可复现、可比较的安全数据。
A.S.E 论文发布后,首周即登上 Hugging Face 日榜与周榜热度第一,体现了行业对「AI 生成代码安全」方向的高度关注与认可。

04 复旦白泽漏洞治理团队介绍
白泽漏洞治理团队聚焦开源代码安全,通过大模型协同程序分析技术解决漏洞治理全生命周期痛点,研究方向涵盖漏洞信息增强、逻辑漏洞挖掘、自动化PoC与补丁生成等关键技术。团队成果已在华为、阿里、中国电信、中远海运等头部企业落地应用,并获2022 Usenix Security 杰出论文奖(国内首篇)、2024 ACM FSE杰出论文奖、上海市技术发明一等奖、工信部网络安全技术应用示范等多项荣誉。此外,团队还获得第九届中国国际互联网+大学生创新创业大赛上海赛区金奖、中国研究生创新实践大赛一等奖、全国大学生信息安全竞赛-作品赛三等奖等荣誉。团队更多相关成果将在后续推送中详细介绍~如果您对我们研究方向感兴趣,请积极联系我们!
联系邮箱:zxl@fudan.edu.cn,张磊老师